Einen großartigen Nest.js-Blog erstellen: Volltextsuche für Beiträge
Emily Parker
Product Engineer · Leapcell

Im vorherigen Tutorial haben wir unseren Blog-Beiträgen eine Bild-Upload-Funktion hinzugefügt.
Mit der Zeit kann man sich vorstellen, dass Ihr Blog jetzt ziemlich viele Artikel enthält. Ein neues Problem tritt allmählich auf: Wie können Leser schnell die Artikel finden, die sie lesen möchten?
Die Antwort ist natürlich die Suche.
In diesem Tutorial fügen wir dem Blog eine Volltextsuchfunktion hinzu.
Sie denken vielleicht: Kann ich nicht einfach eine SQL-Abfrage LIKE '%keyword%' verwenden, um die Suche zu implementieren?
Für einfache Szenarien, ja. Aber LIKE-Abfragen liefern bei der Verarbeitung großer Textblöcke schlechte Ergebnisse und können keine unscharfen Suchen verarbeiten (z. B. wird bei der Suche nach „creation“ nicht nach „create“ gesucht).
Daher werden wir eine effizientere Lösung anwenden: die integrierte Volltextsuchfunktion (FTS) von PostgreSQL. Sie ist nicht nur schnell, sondern unterstützt auch Stemming, Ranking nach Relevanz und bietet Suchfunktionen, die LIKE weit überlegen sind.
Schritt 1: Datenbank-Suchinfrastruktur
Um die FTS-Funktion von PostgreSQL nutzen zu können, müssen wir zunächst einige Änderungen an der post-Tabelle vornehmen. Die Kernidee ist die Erstellung einer speziellen Spalte, die speziell für die Speicherung optimierter, hochgeschwindigkeits-suchfähiger Textdaten vorgesehen ist.
Kernkonzept: tsvector
Wir fügen der post-Tabelle eine neue Spalte vom Typ tsvector hinzu. Diese zerlegt den Titel und den Inhalt des Artikels in einzelne Wörter und normalisiert sie (z. B. verarbeitet sie sowohl „running“ als auch „ran“ zu „run“) für nachfolgende Abfragen.
Ändern der Tabellenstruktur
Führen Sie die folgende SQL-Anweisung in Ihrer PostgreSQL-Datenbank aus, um die Spalte search_vector zur Tabelle post hinzuzufügen.
ALTER TABLE "post" ADD COLUMN "search_vector" tsvector;
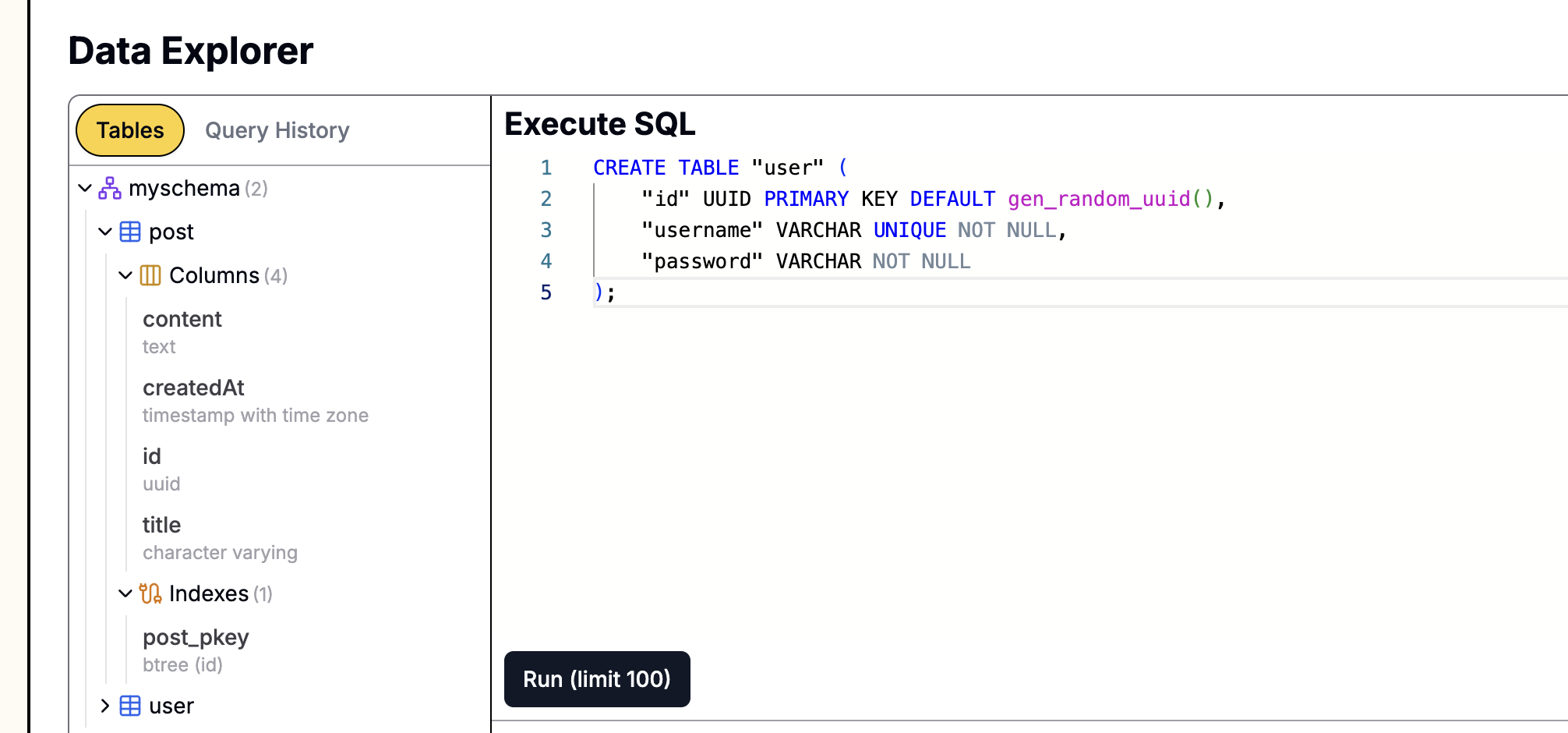
Wenn Ihre Datenbank auf Leapcell erstellt wurde,

können Sie SQL-Anweisungen einfach über die grafische Benutzeroberfläche ausführen. Gehen Sie einfach auf die Seite Datenbankverwaltung auf der Website, fügen Sie die obige Anweisung in die SQL-Schnittstelle ein und führen Sie sie aus.
Aktualisieren des Suchvektors für vorhandene Beiträge
Das Aktualisieren des Suchvektors (search_vector) für Beiträge macht diese durchsuchbar.
Da Ihr Blog bereits einige Artikel enthält, können Sie einfach die folgende SQL-Anweisung ausführen, um search_vector-Daten für diese zu generieren:
UPDATE "post" SET search_vector = setweight(to_tsvector('english', coalesce(title, '')), 'A') || setweight(to_tsvector('english', coalesce(content, '')), 'B');
Automatische Updates mit einem Trigger
Niemand möchte die Spalte search_vector manuell aktualisieren, jedes Mal wenn ein Artikel erstellt oder aktualisiert wird. Der beste Weg ist, die Datenbank diese Arbeit automatisch erledigen zu lassen. Dies kann durch die Erstellung eines Triggers erreicht werden.
Erstellen Sie zunächst eine Funktion, die, wie zuvor, search_vector-Daten für einen Artikel generiert.
CREATE OR REPLACE FUNCTION update_post_search_vector() RETURNS TRIGGER AS $$ BEGIN NEW.search_vector := setweight(to_tsvector('english', coalesce(NEW.title, '')), 'A') || setweight(to_tsvector('english', coalesce(NEW.content, '')), 'B'); RETURN NEW; END; $$ LANGUAGE plpgsql;
Die Funktion
setweightermöglicht es Ihnen, verschiedenen Texten aus verschiedenen Feldern unterschiedliche Gewichte zuzuweisen. Hier setzen wir das Gewicht des Titels ('A') höher als das des Inhalts ('B'), was bedeutet, dass Artikel mit Schlüsselwörtern im Titel in den Suchergebnissen höher eingestuft werden.
Erstellen Sie als Nächstes einen Trigger, der die oben erstellte Funktion jedes Mal automatisch aufruft, wenn ein neuer Artikel eingefügt (INSERT) oder aktualisiert (UPDATE) wird.
CREATE TRIGGER post_search_vector_update BEFORE INSERT OR UPDATE ON "post" FOR EACH ROW EXECUTE FUNCTION update_post_search_vector();
Erstellen eines Suchindex
Erstellen Sie abschließend einen GIN-Index (Generalized Inverted Index) für die Spalte search_vector.
CREATE INDEX post_search_vector_idx ON "post" USING gin(search_vector);
Nun ist Ihre Datenbank bereit für die Suche. Sie wird automatisch einen effizienten Suchindex für jeden Artikel pflegen.
Schritt 2: Erstellen der Suchlogik in Nest.js
Nachdem die Datenbankebene vorbereitet ist, kehren wir zu unserem Nest.js-Projekt zurück, um den Backend-Code für die Verarbeitung von Suchanfragen zu schreiben.
Aktualisieren von PostsService
Öffnen Sie src/posts/posts.service.ts und fügen Sie eine neue Methode search hinzu.
// src/posts/posts.service.ts import { Injectable } from '@nestjs/common'; import { InjectRepository } from '@nestjs/typeorm'; import { Repository } from 'typeorm'; import { Post } from './post.entity'; @Injectable() export class PostsService { constructor( @InjectRepository(Post) private postsRepository: Repository<Post> ) {} // ... andere Methoden bleiben unverändert async search(query: string): Promise<Post[]> { if (!query) { return []; } // Verwenden Sie QueryBuilder, um eine komplexere Abfrage zu erstellen return this.postsRepository .createQueryBuilder('post') .select() .addSelect("ts_rank(post.search_vector, to_tsquery('english', :query))", 'rank') .where("post.search_vector @@ to_tsquery('english', :query)", { query: `${query.split(' ').join(' & ')}` }) .orderBy('rank', 'DESC') .getMany(); } }
Code-Erklärung:
to_tsquery('english', :query): Diese Funktion konvertiert die vom Benutzer eingegebene Suchzeichenfolge (z. B. „nestjs blog“) in einen speziellen Abfragetyp, der mit dertsvector-Spalte abgeglichen werden kann. Wir verwenden&, um mehrere Wörter zu verbinden, was angibt, dass alle Wörter übereinstimmen müssen.@@-Operator: Dies ist der „Übereinstimmungs“-Operator für die Volltextsuche. Die Zeilewhere("post.search_vector @@ ...")ist die Kernoperation, die die Suche durchführt.ts_rank(...): Diese Funktion berechnet einen „Relevanzrang“, basierend darauf, wie gut die Abfrageterme mit dem Blogbeitrag übereinstimmen..orderBy('rank', 'DESC'): Wir sortieren nach diesem Rang absteigend, um sicherzustellen, dass die relevantesten Artikel zuerst angezeigt werden.
Erstellen der Suchroute
Fügen Sie als Nächstes eine neue Route in src/posts/posts.controller.ts hinzu, um Suchanfragen zu verarbeiten.
// src/posts/posts.controller.ts import { Controller, Get, Render, Param, Post, Body, Res, UseGuards, Request, Query } from '@nestjs/common'; // ... andere Importe @Controller('posts') export class PostsController { constructor( private readonly postsService: PostsService, private readonly commentsService: CommentsService, ) {} // ... andere Methoden bleiben unverändert // Neue Suchroute @Get('search') @Render('search-results') async search(@Query('q') query: string, @Request() req) { const posts = await this.postsService.search(query); return { posts, user: req.session.user, query }; } // Da der Controller Routen von oben nach unten abgleicht, muss die :id-Route zuletzt platziert werden @Get(':id') @Render('post') async post(@Param('id') id: string, @Request() req) { // ... } }
Beachten Sie, dass wir die :id-Route zuletzt platzieren, da der Controller Routen von oben nach unten abgleicht, um Konflikte mit der search-Route zu vermeiden.
Schritt 3: Integrieren der Suchfunktionalität in das Frontend
Die Backend-API ist bereit. Fügen wir nun eine Suchbox und eine Seite für Suchergebnisse zur Benutzeroberfläche hinzu.
Hinzufügen der Suchbox
Öffnen Sie die Datei views/_header.ejs und fügen Sie ein Suchformulular zur Navigationsleiste hinzu.
<header> <h1><a href="/">Mein Blog</a></h1> <form action="/posts/search" method="GET" class="search-form"> <input type="search" name="q" placeholder="Beiträge durchsuchen..." /> <button type="submit">Suchen</button> </form> <div class="user-actions"> <% if (user) { %> <span>Willkommen, <%= user.username %></span> <a href="/posts/new" class="new-post-btn">Neuer Beitrag</a> <a href="/auth/logout">Abmelden</a> <% } else { %> <a href="/auth/login">Anmelden</a> <a href="/users/register">Registrieren</a> <% } %> </div> </header>
2. Erstellen der Seite für Suchergebnisse
Erstellen Sie eine neue Datei search-results.ejs im Verzeichnis views. Diese Seite wird zur Anzeige der Suchergebnisse verwendet.
<%- include('_header', { title: 'Suchergebnisse' }) %> <div class="search-results-container"> <h2>Suchergebnisse für: "<%= query %>"</h2> <% if (posts.length > 0) { %> <div class="post-list"> <% posts.forEach(post => { %> <article class="post-item"> <h2><a href="/posts/<%= post.id %>"><%= post.title %></a></h2> <p><%= post.content.substring(0, 150) %>...</p> <small><%= new Date(post.createdAt).toLocaleDateString() %></small> </article> <% }) %> </div> <% } else { %> <p>Keine Beiträge gefunden, die Ihrer Suche entsprechen. Bitte versuchen Sie andere Schlüsselwörter.</p> <% } %> </div> <%- include('_footer') %>
Ausführen und Testen
Starten Sie Ihre Anwendung neu:
npm run start:dev
Öffnen Sie Ihren Browser und navigieren Sie zu: http://localhost:3000/
Schreiben wir einen neuen Artikel mit dem Schlüsselwort „testing“.
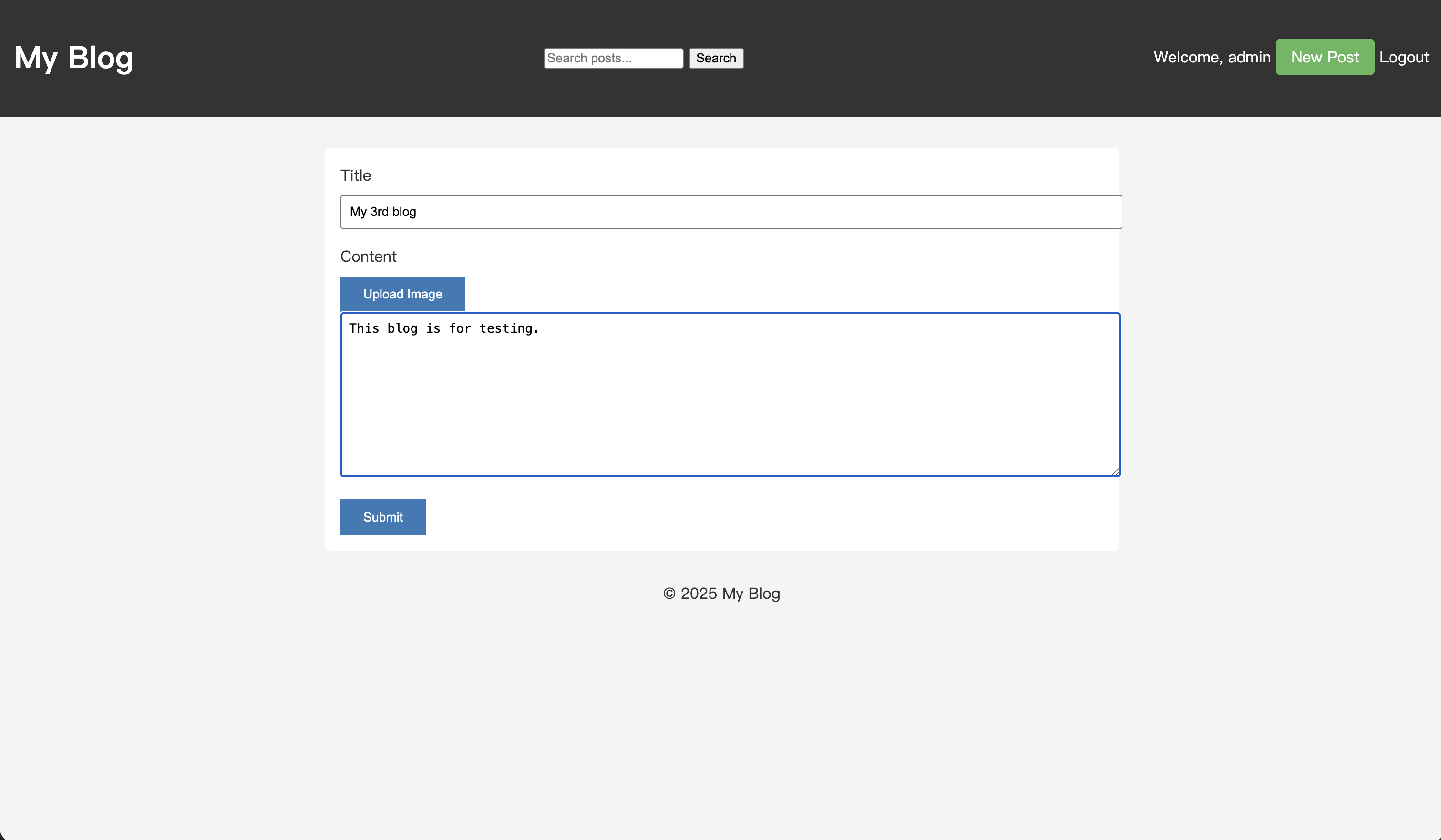
Nachdem Sie den Artikel gespeichert haben, geben Sie „test“ in die Suchbox ein und führen Sie eine Suche durch.
Auf der Seite mit den Suchergebnissen erscheint nun der gerade erstellte Artikel in den Ergebnissen.
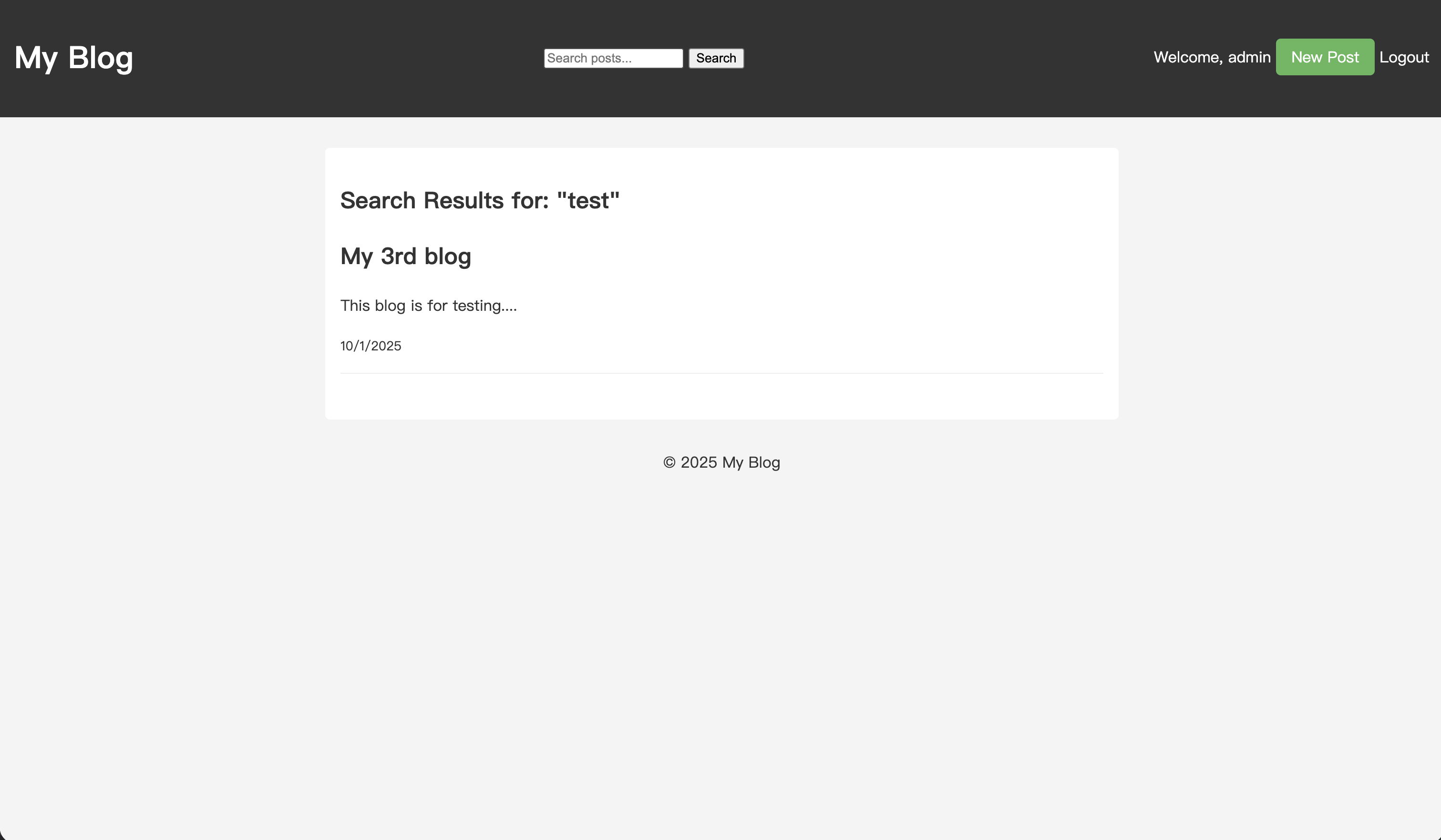
Ihr Blog unterstützt jetzt die Volltextsuche. Egal wie viel Sie schreiben, Ihre Leser werden sich nicht mehr verirren.
Frühere Tutorials:
- Einen großartigen Nest.js-Blog erstellen: Bilder hochladen
- Einen großartigen Nest.js-Blog erstellen: Kommentare beantworten
- Einen großartigen Nest.js-Blog erstellen: Kommentarsystem
- Einen großartigen Nest.js-Blog erstellen: Autorisierung hinzufügen
- Einen großartigen Nest.js-Blog erstellen: Benutzerverwaltung hinzufügen
- 10 Minuten vom ersten Code bis zum Live-Deployment: Ein super-schneller Nest.js Blog-Kurs